Active learning of neuron morphology for accurate automated tracing of neurites
神经元形态主动学习 对 神经轴突的精确自动追踪
阅读本文需要proxy,依赖imgur图床
参考文献:
http://journal.frontiersin.org/article/10.3389/fnana.2014.00037/full
摘要
Automating the process of neurite tracing from light microscopy stacks of images is essential for large-scale or high-throughput quantitative studies of neural circuits. While the general layout of labeled neurites can be captured by many automated tracing algorithms, it is often not possible to differentiate reliably between the processes belonging to different cells. The reason is that some neurites in the stack may appear broken due to imperfect labeling, while others may appear fused due to the limited resolution of optical microscopy. Trained neuroanatomists routinely resolve such topological ambiguities during manual tracing tasks by combining information about distances between branches, branch orientations, intensities, calibers, tortuosities, colors, as well as the presence of spines or boutons. Likewise, to evaluate different topological scenarios automatically, we developed a machine learning approach that combines many of the above mentioned features. A specifically designed confidence measure was used to actively train the algorithm during user-assisted tracing procedure. Active learning significantly reduces the training time and makes it possible to obtain less than 1% generalization error rates by providing few training examples. To evaluate the overall performance of the algorithm a number of image stacks were reconstructed automatically, as well as manually by several trained users, making it possible to compare the automated traces to the baseline inter-user variability. Several geometrical and topological features of the traces were selected for the comparisons. These features include the total trace length, the total numbers of branch and terminal points, the affinity of corresponding traces, and the distances between corresponding branch and terminal points. Our results show that when the density of labeled neurites is sufficiently low, automated traces are not significantly different from manual reconstructions obtained by trained users.
对于神经回路(neural circuits)高通量研究,从光学研究大量图像的神经追踪自动化是必不可少的.
当被标记的神经的通常分布可以被许多自动追踪算法捕获,但事实上分辨神经元分属于不同细胞常常是不可能的.
原因是一些在一堆的神经元常常出现断裂,由于不完美的”神经元的扫描”,其他的还会出现融合,由于光学显微有限的方法.
专业的神经解剖学一般依靠组合信息例如分支节点的距离,分支方向强度,口径,变形,颜色,刺或者棒头的存在.
还有,为了评估不同技术自动化脚本,我们通过上述提到的特点发展出了机器学习.
在用户辅助训练过程中,一种特别设计可信赖的测量适用于主动训练算法.
主动学习显著减少了训练时间,通过提供的少量训练样本,尽可能获取少于1%的一般错误比例.
为了评估算法的总体性能,大量的图像堆被自动重建以及以几个熟练用户手工重建,尽可能完成自动追踪对于基线用户间变异性.
在对比中选择几种追踪方法的几何和技术特征.
这些特征包括了总追踪长度,分支与终点之间的总数和距离,相应追踪的近似程度.
我们的结果表明,当标记神经的密度是足够低的,自动追踪与受过训练的用户来人工重建不会有显著不同.
介绍
Our understanding of brain functions is hindered by the lack of detailed knowledge of synaptic connectivity in the underlying neural network. With current technology it is possible to sparsely label specific populations of neurons in vivo and image their processes with high-throughput optical microscopy (see e.g., Stettler et al., 2002; Trachtenberg et al., 2002; De Paola et al., 2006; Wickersham et al., 2007; Lichtman et al., 2008; Wilt et al., 2009; Ragan et al., 2012). Imaging can be done in vivo for circuit development or plasticity studies (Trachtenberg et al., 2002), or ex vivo for circuit mapping projects (Lu et al., 2009). In the latter case, an unprecedented resolution can be achieved by first clarifying the tissue (Hama et al., 2011; Chung et al., 2013), and then imaging the entire brain from thousands of optical sections (Ragan et al., 2012). The overwhelming obstacle remaining on the way to brain mapping is accurate, high-throughput tracing of neurons (Sporns et al., 2005; Lichtman et al., 2008; Miller, 2010; Gillette et al., 2011b; Kozloski, 2011; Lichtman and Denk, 2011; Liu, 2011; Svoboda, 2011; Helmstaedter and Mitra, 2012; Van Essen and Ugurbil, 2012; Perkel, 2013). Presently, accurate traces of complex neuron morphologies can only be obtained manually, which is extremely time consuming (Stepanyants et al., 2004, 2008; Shepherd et al., 2005), and thus impractical for large reconstruction projects.
在底层神经网络中对于突触连通的细节知识的缺失阻碍了我们对脑功能的理解.
用现代技术是可能去少量标记特定的神经群,在vivo和通过高通量光学显微镜得到的图像.
成像可以在vivo完成,为了神经线路的发展或者粘性研究,或者前vivo对于神经线路测绘工程.在后来发展中,一种崭新的解决方案可以实现对组织的第一清晰度和形成整个大脑的图像变成数以前千计的光学切片.巨大的阻碍留在了如何完成大脑映射:精确高通量的神经元追踪.
目前,复杂神经元形态的精确追踪只能手工获得,这是极端耗时的,因此,对于大型重建工程是不切实际的.
Many automated tracing algorithms have been developed in recent years [see e.g., Al-Kofahi et al., 2002; Schmitt et al., 2004; Zhang et al., 2007; Al-Kofahi et al., 2008; Losavio et al., 2008; Peng et al., 2010; Srinivasan et al., 2010; Bas and Erdogmus, 2011; Peng et al., 2011; Turetken et al., 2011; Wang et al., 2011; Xie et al., 2011; Bas et al., 2012; Choromanska et al., 2012; Turetken et al., 2012 and Meijering, 2010; Donohue and Ascoli, 2011; Parekh and Ascoli, 2013 for review]. In general, existing algorithms can accurately capture the geometrical layout of neurites but are not guaranteed to recover their correct branching topology (Figure 1). Topological errors are inevitably present in traces obtained from low signal-to-noise images, images of non-uniformly labeled neurites, or images with high density of labeled structures. Close examination of such traces often reveals topological errors such as broken branches, missing branches, and incorrectly resolved branch crossover regions (stolen branches). This is a particular concern for high-throughput projects where topological errors can accumulate over multiple stacks. For example, while tracing a long-range axon from one optical section to the next, even a very low error-rate, say 5% per section, will almost certainly lead to erroneous connectivity after about 20 sections (typically about 10 mm), rendering the trace unusable for brain mapping projects. Clearly, the rate of topological errors in automated reconstruction projects must be carefully controlled (Chothani et al., 2011).
在近年来许多自动追踪算法已经发展,在一般情况下,现存的算法可以精确捕获到神经元的几何布局,但是不保证恢复正确分支节点的技术.
从低信噪比图像和非均匀地标记的神经突的图像中,对于现存的追踪获取,技术错误是不可避免的.
这样的追踪方法在仔细检查下,常常会发现技术错误,例如破碎的分支,缺失的分支,和错误解决的分支交叉区域.这是备受关注的高通量项目,拓扑学错误可以累积多个堆栈中,例如,当追踪长轴突从一个光学切片到下一个,即使是一个非常低的错误率,如每切片5%,几乎毫无疑问地导致错误的连通性,在大约20个切片后(通常是十毫米),致使这个追踪是不能用的对于大脑映射工程.明显的,技术错误的几率在自动化重建工程必须是小心地被控制的.
In this study we describe an active machine learning approach (Settles, 2012) that has the potential to significantly reduce the number of topological errors in automated traces. Our algorithm first detects a geometrically accurate trace with the Fast Marching method (Cohen et al., 1994; Cohen and Kimmel, 1997; Sethian, 1999; Mukherjee and Stepanyants, 2012), which was extended to incorporate multiple seed points. Next, the initial trace is dismantled to the level of individual branches, and active learning is applied to reconnect this trace based on knowledge of neuron morphology. We show that active learning does not require large sets of training examples, and the results generalize well on image stacks acquired under similar experimental conditions. What is more, when the density of labeled neurites is sufficiently low, automated traces are not significantly different from reconstructions produced manually by trained users.
方法
Results of this study are based on the analyses of two datasets featured at the DIADEM challenge (Brown et al., 2011). The OP dataset includes 9 image stacks containing axons of single olfactory projection neurons from Drosophila (Jefferis et al., 2007), and the L6 dataset consists of 6 image stacks containing axons of multiple layer 6 neurons imaged in layer 1 of mouse visual cortex (De Paola et al., 2006). The NCTracer software (www.neurogeometry.net) was used to trace each image stack automatically, as well as manually. The manual traces were generated independently for each stack by three trained users.
这项研究的结果是基于两个有特点的数据集在”王冠”的挑战.这OP数据集包括了9个图像堆,包含了果蝇属的单嗅觉工程神经集的轴突,和由6图像堆组成的L6数据集,包含了多层次的6个神经在小鼠视觉皮层的1层成像的轴突.NCTracer软件(www.neurogeometry.net)是被用于自动化追踪每一个图像堆,同时也可以手工.对于每一个图像堆,通过三个训练有素的用户,这手工追踪可以被独立生成.
神经元的初始化追踪
The Initial Trace of Neurites
We refer to any trace providing geometrically accurate information about the layout of neurites within an image stack as an initial trace. Numerous segmentation and tracking-based methods (see e.g., Al-Kofahi et al., 2002; Schmitt et al., 2004; Zhang et al., 2007; Al-Kofahi et al., 2008; Losavio et al., 2008; Peng et al., 2010; Srinivasan et al., 2010; Bas and Erdogmus, 2011; Peng et al., 2011; Turetken et al., 2011; Wang et al., 2011; Xie et al., 2011; Bas et al., 2012; Choromanska et al., 2012; Turetken et al., 2012) can be used to produce initial traces. In this study we adapt the Fast Marching method (Cohen et al., 1994; Cohen and Kimmel, 1997; Sethian, 1999; Mukherjee and Stepanyants, 2012) to grow the initial trace from multiple seed points (Figure 2), analogous to the way light from multiple point sources spreads through a non-uniform medium. This process is described by the Eikonal boundary value problem (Sethian, 1999):
我们查阅了任何一种追踪都带着在几何学上精确的信息,如神经元的布局,使用一个图像堆作为初始追踪.
许多分隔和基于追踪的方法可以用来产生初始追踪,在这项研究中,我们选用了快速行进的方法 (Cohen et al., 1994; Cohen and Kimmel, 1997; Sethian, 1999; Mukherjee and Stepanyants, 2012)从多个种子点去扩张初始追踪,类似于光线从多个点源通过非均匀媒介中传播.这个进程被描述为 光程函数边值问题(Sethian, 1999).

In this expression, vector r represents a position in the image stack (or non-uniform medium), I is the image intensity normalized to the 0–1 range (analog of the speed of light in the medium), and ∇ denotes the gradient operator. Light rays originate from the boundary, ∂S, at time zero, and the time map, T(r), provides information about the shortest time of arrival of these rays to various locations in the image. Because higher image intensities correspond to faster speeds of light propagation, the arrival time front in the image will preferentially spread along the high intensity structures of neurites (see Figure 2C).
在这个表达式中,矢量r代表在图像堆中或是在非均匀媒介中的位置,I是图像亮度 归于0-1范围内(类似于光在介质中的速度),∇代表梯度操作子.
光射线起源于边界,∂S在零时间,和时间对应,T(r)提供了在极短时间内这些光线到达图像中的不同位置的信息.因为更高的图像亮度代表着光传播的更快的速度.在到达时间前,图像将会优先传播沿着高亮度结构的轴突.
The Fast Marching algorithm of Sethian (Sethian, 1999) is an efficient numerical scheme for solving the Eikonal boundary value problem, Equation (1). Since the speed function in our problem is defined by the image intensity, it is always positive. For positive speed functions it is known that the Eikonal boundary value problem can be solved more efficiently than the commonly used alternative—the Hamilton-Jacobi problem of the Level Set method (Sethian, 1999). One reason is that the stability condition required for a numerical solution of the time-dependent Level Set equation is more stringent than that used to solve the Eikonal problem. Specifically, this condition requires very small time steps and thus the Level Set method is expected to be more time consuming. The second advantage of Fast Marching has to do with the outward only propagation of the fronts, which can be used to find new front points very efficiently (Sethian, 1999).
Sethian 的快速行进算法是一个高效数值方案对于求光程函数边界数值问题(方程1),在我们的问题中,速度被定义成图像的亮度,它始终为正,对于正速度函数,众所周知,在光程函数边值问题上,可以比常用的替代方法[the Hamilton-Jacobi problem of the Level Set method (Sethian, 1999)]更有效地解决。原因之一是,对于随时间变化的水平集方程的数值解所需的稳定性条件是更苛刻的,比用于解决光程函数边界数值问题。特别得,这种情况需要非常小的时间间隔,因而水平集方法预计将耗费更多的时间。快速行进的第二个优点是只在前沿,向外传播,它可用于非常有效地找到新的前进点 (Sethian, 1999).
We implement the Fast Marching algorithm (Sethian, 1999) on a discrete lattice defined by the centers of image voxels, l = (i, j, k)T. Here the time map is evolved from the boundary at T = 0 by taking the upwind solution of a discretized version of Equation (1):
我们实现快速行进算法在离散点阵形式通过图像像素的中心定义, l = (i, j, k)T.这里的时间映射是从在T = 0的边界演变,采用方程的离散版本的upwind解决方案.

Parameters (sx, sy, sz) in this expression denote the voxel dimensions which may not be the same due to a typically lower z-resolution in confocal and two-photon microscopy images.
参数(i,j,k)在这个表达式代表三维尺寸,并不相同由于一般低z分辨率在共焦和双光子显微镜图像.
The arrival time front is initialized with T = 0 at multiple seed points, which are automatically generated along the structure of neurites based on image intensity (Figure 2A). As was previously described (Mukherjee and Stepanyants, 2012), the arrival time front is allowed to travel a specified distance, Dmax, to establish a local time map. The value of Dmax has to be chosen based on two considerations: Dmax has to be larger than the caliber of neurites (3–5sx for OP and L6) not to produce short spurious branches and, at the same time, not much larger than the shortest branch that needs to be resolved by the algorithm (10sx in this study). Dmax = 15sx was used throughout this study. The path connecting the farthest point of the front to the T = 0 boundary is then found by performing gradient descent on T(i, j, k) (see Figures 2C–E). Next, the gradient descent path is added to the boundary ∂S and the Fast Marching algorithm is re-initialized from the new boundary. This process continues until a stopping condition is reached, at which point the final ∂S defines the initial trace. The stopping condition used in this study is based on the average intensity of the last added branch. When this intensity falls below a set threshold (typically 20% of the average intensity of the existing trace), Fast Marching is paused and can then be continued or terminated by the user.
在达到时间前是用T = 0在多个种子点进行初始化,是用于自动生成沿着神经元结构基于图像亮度.如先前所描述(Mukherjee and Stepanyants, 2012),在到达时间前,是被允许行进规定距离,Dmax 是建立了当地时间映射,Dmax的值基于两个方面考虑:Dmax必须比轴突的口径更大,(3–5sx for OP and L6)不产生短伪分支,与此同时,不比需要由算法来解决的最短分支大得多(10SX在这项研究中).在整个本研究中使用DMAX = 15sx。该路径连接最接近到T = 0的边界前的最远点的路径,然后由于T(I,J,K)(参见图2C-E)进行梯度下降找到.
接下来,梯度下降通道被添加到边界∂S,快速行进算法从新的边界被重新初始化.
此过程继续进行,直到达到终止条件.在该点,最终∂S表示初始轨迹.在此研究中使用的停止条件是基于最后添加分支的平均强度.当该亮度降到低于设定的阈值(通常是已经存在的追踪的平均亮度的20%),快速行进被暂停,然后可以由用户继续或终止.
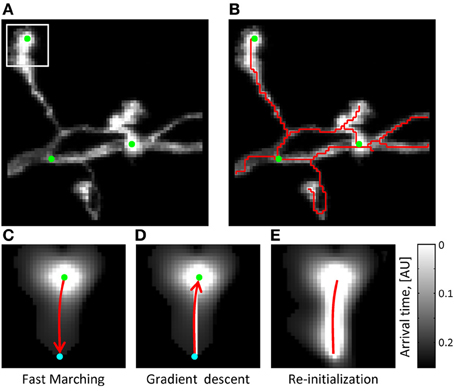
As long as the seed points used to initialize Fast Marching are located in the foreground and are connected by higher than background intensity paths, their Fast Marching fronts are guaranteed to collide. The gradient descent algorithm is invoked in this case as well. Here, gradient descent paths originating from the collision voxel back-propagate into every colliding region, thus connecting their T = 0 boundaries. If there is a break in intensity along a neurite linking two seed points, the Fast Marching algorithm may terminate before the fronts have a chance to collide. In addition, high levels of background intensity may lead to erroneous front collisions. These and other topological errors in the initial trace will be corrected as described in the following sections.
只要位于前景种子点通常用快速行进的初始化 而且是 通过比背景亮度更强的路径来连接, 快速行进的前端一定会碰撞. 在这个场景下,梯度下降算法效果很好,梯度下降路径起点从碰撞的三维像素反向传播到每一个碰撞的区域,因此连接到T=0的边界中.如果在亮度上有断开在神经元的两个种子点之间,快速行进算法也许会停滞在可能碰撞的前端.此外,高亮度的背景会导致接触前端的错误.在接下来所描述的部分,这和其他算法的错误在初始化追踪中将被纠正,
Optimization of the Initial Trace
优化初始追踪
We represent the initial trace as a graph structure consisting of nodes linked by straight line segments. Each node, k, is described by its position in the stack, rk = (xk, yk, zk)T, and the caliber, Rk, of the neurite at that location. Information about connectivity among the nodes is stored in the adjacency matrix, A. We find this representation to be more convenient than the traditional SWC format of neuron morphology (Cannon et al., 1998) because the latter cannot be used to describe structures containing loops.
由直线所连接的节点组成的图形结构作为初始轨迹.每一个节点,k都用来描述它在图像栈的位置, rk = (xk, yk, zk)T,神经突起的口径:Rk,储存在邻接矩阵的节点间的连通性信息,我们发现,这表示要比传统的神经元形态SWC格式更实用 (Cannon et al., 1998)因为SWC无法描述包含回环的结构。
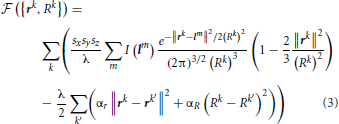
Because the initial trace lies sufficiently close to the centerline of neurites, this trace can be optimized by monitoring its fitness in response to small changes in the position and caliber of every node. The fitness function used in this study, yes, consists of the intensity integrated along the trace and regularizing constraints on the positions and calibers of the connected nodes:
因为初始追踪位置十分接近神经的中间线,追踪可以通过监测它适应的每一个节点的位置和口径的微小变化去优化.在这项研究中,使用的适应调整功能,是由轨迹的整体亮度和连接节点的口径与位置的规则约束所组成的
Vectors rk in this expression specify the positions of the trace vertices, while vectors lm denote the positions of voxel centers in the image stack. Index k’ enumerates the neighbors of vertex k. Parameter λ denotes the average density of nodes in the trace, i.e. the number of nodes per voxel. Lagrange multipliers αr > 0 and αR > 0 control the stiffness of the regularizing constraints. The first term in this expression is the convolution of the image with the Laplacian of Gaussian. This convolution can be performed by using the Fast Fourier Transform (Press, 2007) or, in case of relatively small density of trace nodes, it may be faster to perform explicit summation over the index m. In this case, due to the fast decay of the Gaussian factor, the summation can be restricted to a small number of voxels in the vicinity of the trace (see Chothani et al., 2011 for details).
在这个表达式中,向量Rk指的是追踪顶点的位置,而向量lm表示在图像堆栈三维像素中心的位置,参数λ表示节点在跟踪的平均密度,即每像素节点的数目.拉格朗日乘子αR> 0,αR> 0控制的正则化约束刚度.在该表达式中的第一项是与高斯的拉普拉斯图像的卷积。这个卷积可以通过使用快速傅里叶变换(Press,2007年),或在跟踪节点的相对较小密度的情况下进行,它可以是更快地通过索引号m执行显式求和。在这种情况下,由于高斯因子的快速衰减,求和可以限制到一个小数目在跟踪的附近的体素(see Chothani et al., 2011 for details)。
Maximization of the fitness function, yes, is performed with Newton’s method (Press, 2007):
最优适应函数是牛顿法
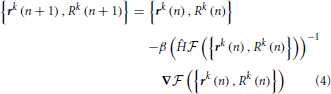
Variable n in this expression enumerates the iteration steps of the algorithm, parameter β > 0 controls the step size, Ĥ denotes the Hessian operator acting on all the node variables {rk(n), Rk(n)}, and -1 in the exponent denotes matrix inversion. The positions and calibers of all nodes of the trace, including branch and terminal points, are synchronously updated at every iteration step. The values of all three terms in the fitness function are monitored during optimization. Optimization is terminated once the relative changes in all three quantities fall below 10−8. For the OP and L6 datasets considered in this study, the optimization procedure typically converges to the optimum solution in less than 50 steps. Optimization improves the layout of branches as well as the placement of branch and terminal points in the initial trace (Vasilkoski and Stepanyants, 2009; Chothani et al., 2011). The values of parameters αr, αR, and β are constrained by the considerations of algorithm stability, speed of convergence, and accurate representation of neurites’ curvature and caliber. Some of these issues were discussed in Vasilkoski and Stepanyants (2009) and Chothani et al. (2011).
在此表达式变量n列举算法的迭代步骤中,参数β> 0的控制步长,h表示作用于所有节点的变量{RK(n)时,RK(n)}存储在黑森操作者,和-1中的指数表示矩阵求逆。的位置和跟踪,包括分支和终点的所有节点的口径,同步地在每个迭代步骤更新。在健身功能的所有三个术语的值优化过程中进行监控。一旦在所有三个量的相对变化低于10-8优化终止。对于本研究中考虑的OP和L6数据集,所述优化过程通常收敛于小于50步的最佳解决方案。优化提高分支的布局,以及在初始跟踪转移和终点的位置(Vasilkoski和Stepanyants,2009; Chothani等人,2011)。参数值αR,αR,β是由算法稳定性,收敛的速度,和突起’曲率和口径的精确表示的考虑因素的限制。其中的一些问题进行了Vasilkoski和Stepanyants(2009年)和Chothani等人讨论。 (2011年)。
Learning Branching Morphology of Neurites
学习轴突分支形态
As shown in Figure 1, even when the initial trace accurately describes the geometry of neurites, it often fails to capture the correct branching topology. To address this problem, we disconnect branches of the initial trace from one another and then assemble them into tree-like structures based on prior knowledge of neuron morphology. In order to discriminate between correct and erroneous ways to assemble branches, different branch merging scenarios are evaluated in a machine learning approach by combining information about various features of the trace. Such features may include distances between branches, branch orientations, average intensities, intensity variations, branch thicknesses, curvatures, tortuosities, colors, and presence of spines or boutons. Features 1–9 of Figure 3 were used to produce the results of this study. These features were selected based on our knowledge of neuroanatomy and intuition gained from manual neuron tracing. We carefully examined the decisions we make when faced with branch merging tasks and initially created a list of 17 features that are shown in Figure 3. Features 15 and 16 are not applicable for the OP and L6 datasets as these datasets include grayscale images of axons only. Features 10–14 and 17 were tested but did not improve the performance of the classifiers. This is why the above features (10–17) were left out of the analysis. This is not to say that features 10–17 are not important; they may be useful for other dataset types.
如图一,即使初始追踪点准确描述神经元几何形状,但它往往不能捕捉到正确的分支的拓扑.为了解决这个问题,我们从中分离各个初始节点的分支和根据神经元形态学的先前知识组合它们成树状结构.为了辩别真假分支节点的通路,不同的分支节点合并脚本在机器学习中优化,通过组合追踪的多样特点信息,这些特点包括分支距离,分支方向,平均亮度,亮度变动,分支厚度,导致弯曲的因素,弯曲,颜色,神经轴突的存在.特征图3的1-9生成本研究的结果.根据我们人工跟踪神经元得到的解剖学与直觉的知识来选择这些特性。我们仔细审核我们所做的决定–对于分支合并任务和初始创建特征图3的17的列表,如图3所示功能15和16不适用于OP和L6数据集,这些数据集只包括轴突的灰度图像。特征图10-14和17进行了测试,但没有提高分类的效果。这也是为什么上述特征图(10-17)被排除分析。这并不是说,具有10-17并不重要;它们可以是用于其他数据集类型是有用的。
To evaluate different branch merging patterns in the disconnected initial trace we cluster branch terminal points on the basis of their relative distances.
为了改善不同分支合并的模式在分离初始追踪,我们在它们相对距离的基础上连接分支末端.
For this, we first create an all-to-all connected graph in which nodes represent the branch terminal points. Next, the links between distant nodes (>10sx) are removed, exposing the clusters of nearby branch points.
为此,我们首先创造了代表分支节点末端的一个节点的全部连接图形,接下来,距离>10sx的线会被移走,出现临近分支节点的集群.
The threshold distance of 10sx was chosen based on two considerations.
基于两方面考虑选择了10sx的阈值距离:
First, this distance has to be larger than the voxel size (sx) and the size of a typical gap in intensity resulting from imperfect labeling of branches (0 for OP and ~5sx for L6).
首先,这个距离必须比三维像素尺寸(SX) 和 在亮度上,由于不好的标记分支得到的一个典型间隙大小(0为OP和〜5SX为L6) 要大.
Second the threshold distance has to be smaller than the typical branch length (20sx-50sx for OP and L6).
第二,这个阀值距离必须小于典型分支长度(20sx-50sx对于OP和L6).
Results of branch merging are not sensitive to the precise value of this parameter in the 5sx–15sx range. Branch merging is examined within each cluster of branch terminal points independently.
在精确到5SX-15sx范围内参数,分支合并的结果是不明显的.在每一个独立的分支末端点集群中,分支合并是被检查.
Within a given cluster, all possible branch merging scenarios are considered (Figure 4A), and the correct merging pattern is determined in a classification framework.
在给定的群集中,我们会考虑采用所有可能的分支合并方案(图4A),和在一个分类框架,去确定正确的合并模式.
Clusters containing 2 terminal points lead to two scenarios, i.e., to connect or not to connect the terminal points.
包含了两个末端点的多集群将导致两种情况:连接或不连接末端点.
Three terminal point clusters result in 5 scenarios, 4 terminal point clusters lead to 15 (Figure 4A), and the number of scenarios increases exponentially with the complexity of clusters (Figure 4B).
三个末端点的集群将导致五种结果,四个末端点的集群将导致十五种结果(图4A),和结果的数目与集群的复杂性(图4B)呈指数增大。
This exponential increase gives a unique advantage to our classification approach to branch merging.
对于进行分支合并的分类,该指数增长提供了一个独特的优势.
Generally, machine learning applications require large sets of labeled data.
一般情况下,机器学习应用需要大量标记数据。
Creating such sets can be very time-consuming and, in many cases, impractical.
创造这样的集合是非常费时,在许多情况下,不实用。
Our training strategy circumvents this problem by exploiting the large numbers of branch merging scenarios.
我们的训练策略是利用大量的分支合并方案去规避了这一问题。
Labeling the correct branch merging scenario in a single cluster can provide thousands of training examples.
在一个集群中提供数以千计的例子去标记一个正确的分支合并方案.
Hence, it becomes possible to train the classifier in real time and obtain accurate results by labeling only 10–100 clusters of branch terminal points.
因此,在现实中有可能训练出分类器,通过仅仅标记10-100个分类末端点的集群去获取精确的结果.
All possible branch merging scenarios are evaluated within a given cluster of branch terminal points.
在给定的分支末端节点集群中,所有可能的分支合并的方案都会被评估.
Each scenario, i, is characterized by a feature vector xi (Figure 4A) whose components consist of features of the trace that may be important for selecting the correct branch merging scenario (Figure 3).
每个方案其特点是一个特征矢量xi(图4A),其组件包括可能是重要的追踪的特性,对于筛选正确的分支合并方案(图3)。
The problem is thus reduced to learning the best set of weights, w, for discriminating between the correct and erroneous scenarios within every cluster.
因此,对于如何辨别每个集群中正确还是错误的方案,这个问题被简化为如何得到最好权重W,

This formulation leads to another important advantage for the implementation of the classification strategy. Due to the linearity of the problem, Equation (5) can be rewritten as,
这公式对于实现分类策略有其他重要优势。由于问题是线性的,方程式如下

resulting in a subtractive normalization of the feature vectors within individual clusters.
这导致在独立集群的特征向量的消减归一化。
Because branch merging scenarios are only compared within clusters, Equation (6) effectively normalizes for the variations in image intensity and density of neurites across clusters.
因为分支合并方案只能在集群中比较。方程6可以高效归一对于图像亮度和集群中神经的密度的变化
The classification problem of Equation (6) is solved with sign-constrained perceptron (Engel and Broeck, 2001) or SVM classifiers (Wang, 2005), which were modified to be able to account for the relative importance of some training examples.
用sign-constrained perceptron (Engel and Broeck, 2001) or SVM classifiers (Wang, 2005)可以解决方程6的分类问题,这被修改,可以解释一些训练例子的相对重要性。
The sign-constrained perceptron algorithm was previously described in Chapeton et al. (2012):
sign-constrained perceptron算法以前在Chapeton et al. (2012)如下描述:

where w is the weight vector of the perceptron classifier, Δxμ is the difference between the feature vectors for the erroneous merger μ and the correct merger from the same cluster,
w表示感知分类的权重向量, Δxμ表示在相同集群中错误合并μ和中正确合并分支的特征向量不同,
N is the number of features (9 features were used in this study), and m is the number of comparisons made (total number of scenarios minus number of clusters).
N指的是特性数字(在该研究中9特征),和m是压缩模式中的数字(总方案除以集群数量)。
The value of the parameter gk can be set to −1 or 1, constraining the corresponding weight, wk, to be negative or positive, or set to 0, in which case the weight is unconstrained.
参数gk的值设置为-1或者1,限制相应的权重,wk,加强或减弱,或者设置为0,使得权重无限制。
Because larger distances, overruns, and offsets of terminal points (see Figure 3) decrease the likelihood that branches should be merged, the weights of these features were constrained to be positive.
因为更长距离,末端点的偏移或超出(见图3),减少了分支该合并的可能,这些特征权重是趋向于加强。
In addition, the weight associated with the number of free terminal points was constrained to be positive to promote branch merging.
此外,权重因自由末端的数量的提高,而改善分支合并。
All other weights were left unconstrained as we did not have clear motivation for doing otherwise. Hence, g = (1,1,1,0,0,0,0,0,1)T was used in this study.
其他权重不限制,因为我们没有明确动机去做,除非,g=(1,1,1,0,0,0,0,0,1)T会被使用在这个研究中。
Parameter κ is referred to as the perceptron robustness (analogous to SVM margin). Increasing κ should initially improve the generalization ability of the perceptron,
参数k引用作为健壮性(类似于SVM的边缘)。K的增加应该最初改善感知器通用能力。
but as the perceptron fails to correctly classify a progressively increasing number of training examples, this generalization ability should decrease.
但由于当训练样本数增加,感知器无法正确分类,这种通用能力应该减少。
We used the leave-one-out cross-validation scheme to examine this trend. In this scheme, training is done on all but one labeled example, and the remaining example is used for validation.
我们用了差一法、交叉验证去检验这个趋势,所有训练样本完成后,除了一个用来标记,其余都用于验证。
In Figure 5 each branch merging cluster was used once for validation and the results were averaged. Figure 5A shows that there is a large range of κ for which the perceptron performs reasonably well for both L6 and OP datasets.
在图像5,每一个分支合并集群用于验证,结果是平均的。图5a显示当有大量κ,感知器的表现相当不错,L6和OP的数据集。
The value of κ was set to 1 throughout this study.
在本研究,κ的值被设置为1。
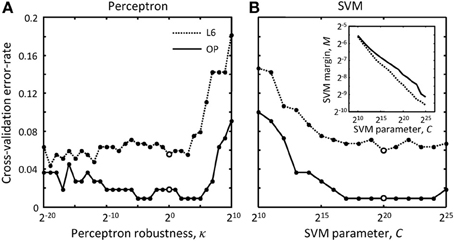
Figure 5. How to choose best classification parameters. (A) Leave-one-out cross-validation error-rate as function of the perceptron robustness parameter, κ [see Equation (7)].
图5,如何选择最好的分类参数.归一法 交叉验证错误几率作为感受器健壮性功能的参数,κ [见方程(7)].
(B) Same error-rate as function of the SVM parameter, C [see Equation (9)].
相同错误几率作为SVN功能的参数,C [见方程(9)].
The inset shows how SVM margin, M, depends on C. Solid and dotted lines show the results for the OP and L6 datasets respectively.
这插入物显示了SVN是怎样留白,M,依赖于C.实线与点状线分别显示了OP与L6结果集的实验结果.
Large empty circles indicate the parameter values that were used throughout this study, κ = 20 and C = 220.
大空心环表明了这个研究始终使用这个参数值,K=20和C=220.
The sign-constrained perceptron problem of Equation (7) was solved by using a modified perceptron learning rule (Engel and Broeck, 2001):
使用更变后的感受器学习规则解决了该方程式7的符号约束感受器问题(Engel and Broeck, 2001):

Δw=θ(κN−1NwTΔxμ)1NΔxμ wk=wkθ(wkgk), k=1,2,…,N (8)
In this expression, Δw denotes the change in the perceptron weight vector in response to presentation of the training example μ;
在这个表达式中, Δw表明在感受器权重向量的改变将影响训练例子μ的感受器.
θ is the Heaviside step function, which is defined to be 1 for non-negative arguments and zero otherwise.
θ是海维赛德阶跃函数,是定义为1,为了非负参数与0.
The step functions in Equation (8) ensure that training is not done on learned examples, and that the perceptron weights violating the sign-constraints are set to zero at every step of the algorithm.
该阶跃函数在方程8确保了这个训练是没有在已经学习过的例子中做过,在算法中的每一步中,当感受器违反符号约束,权重被设为0.
Perceptron weights are updated asynchronously by training on examples, μ, that are drawn from the set of all examples with probabilities proportional to user-defined cluster weights, Qμ.
感受器权重是随着例子训练不断同步更新, μ,从所有例子中有概率比例对于用户定义集群权重得到,Qμ.
All cluster weights are initially set to 1 and can be modified by the user to increase the probabilities with which examples from some clusters come up for training.
所有集群权重初始化设置为1,可以被用户修改,增加概率,在训练中出现一些集群的例子.
This makes it possible to enforce learning of certain rare branch merging topologies.
这尽可能使得可学习某些特殊分支合并的拓扑结构.
Though user-defined cluster weights may be used to improve the outcome of training, this feature was not examined in the present study to avoid subjectivity associated with different choices of Qμ.
通过用户定义的集群权重可以用于改善训练的输出结果,这个特性是没有审核在现在的研究的,为了避免主观联系Qμ的不同选择.
An SVM classifier can also be used to solve the system of inequalities in Equation (6). To incorporate the used-defined cluster weights, Qμ,
在方程式6,一个SVN分类器可以被用于解决系统的不均等.去组成用户定义的集群权重,Qμ,
we modified the standard formulation of the SVM problem (Wang, 2005), and in this study maximize the following dual Lagrangian function in order to obtain the SVM weight vector w:
我们修改SVN问题(Wang,2005)的标准参数,和在该研究中,最大化以下双拉格朗日函数去获取SVN权重向量w:

In these expressions, l is the number of SVM support vectors and C is the SVM margin (see the inset in Figure 5B).
在这表达式中,l是SVN支持向量的数量,C是SVN留白(见插入物在图5B).
Similar to the perceptron robustness, there is a large range of values of C for which the SVM produces reasonably good generalization results for both datasets.
类似于感受器健壮性,这大范围的C值可以使得SVN生产出合理而好的通用结果,对于这两个数据集.
C = 220 was used to produce results of this study. Again, all used-defined cluster weights, Qμ, were set to 1 during training.
C=220被用于产出该研究的结果,再次,所有用户定义的集群权重 Qμ,都被设为1在训练期间.
Active Learning Strategy
主动学习策略
In this section we describe a pool-based sampling approach (Lewis and Gale, 1994) that can be used to actively train the Perceptron and SVM classifiers on branch merging examples.
在这一部分,我们描述一个基于池抽样方法 (Lewis and Gale, 1994),用于积极训练感受器和SVM分类器在分支合并的例子中.
In this approach the user selectively draws queries from the pool of all branch merging clusters based on the value of the confidence measure:
这这个方法,用户并不普遍画出问题从所有分支合并集群池中,基于信任的测量值:
Confidence=e−wTxcorrect merger/T∑i∈allmergerse−wTxi/T (10)
This measure assigns low confidence values (in the 0–1 range) to clusters in which the erroneous merging scenarios are located close to the decision boundary defined by w.
在这个测量分配低可信值(在0-1范围)对于使用错误合并方案的集群接近判定边界由w定义.(err)
Parameter T controls the spread of confidence values but does not affect their order.
参数T包含了可信值的范围除了不影响他们的规则.
This parameter was set to 1 throughout the study. Training can be performed after labeling a single or multiple low confidence clusters, and the confidence measure is updated after each training step.
在该研究中,这个参数是设定为1.训练可以实施,在边界单个或多个低可信集群和可信测量是被更新的在每一步训练后.
It is absolutely essential that clusters in which the correct merging scenario cannot be identified with high certainty should not be used for training,
绝对的是,高度肯定的正确合并方案不能被识别的集群是不能作为训练样本的.
as a small number of errors in the labeled set may significantly worsen the performance of classifiers.
即使是作为小错误在标记集群中也许会极大地使得分类器的性能下降.
Results
结果
The methodology described in this study is implemented in the NCTracer software for automated tracing of neurites.
在本研究中,该方法论以NCTracer软件进行自动追踪神经进行演绎.
This methodology consists of two major parts—initial tracing and branch merging.
改方法论包含了两个主要部分初始化追踪和分支合并部分.
In the first part, an initial trace is created by using the Voxel Coding (Zhou et al., 1998; Zhou and Toga, 1999; Vasilkoski and Stepanyants, 2009) or the Fast Marching (Cohen et al., 1994; Cohen and Kimmel, 1997; Sethian, 1999; Mukherjee and Stepanyants, 2012) algorithm, and optimized to ensure that the trace, including its branch and terminal points, conforms well to the intensity in the underlying image (see the Methods section for details).
在第一部分,一个初始追踪使用三维像素编码(Zhou et al., 1998; Zhou and Toga, 1999; Vasilkoski and Stepanyants, 2009) 或是快速行进算法(Cohen et al., 1994; Cohen and Kimmel, 1997; Sethian, 1999; Mukherjee and Stepanyants, 2012) 所创造,优化去确保该追踪,包括它的分支和末端点,确保亮度在下层图像中(见方法部分的细节).
Below we examine the initial traces from two very different dataset types: axons of single olfactory projection neurons from Drosophila (OP dataset, n = 9 image stacks) (Jefferis et al., 2007) and axons of multiple layer 6 neurons imaged in layer 1 of mouse visual cortex (L6 dataset, n = 6 image stacks) (De Paola et al., 2006).
我们从两个差异大的数据集中审核初始追踪点:来自果蝇的单嗅觉轴突神经工程(OP dataset, n = 9 image stacks) (Jefferis et al., 2007)和小鼠视皮层一层的多层6神经轴突 (L6 dataset, n = 6 image stacks) (De Paola et al., 2006).
These datasets were featured at the DIADEM challenge (Brown et al., 2011) and serve as benchmarks for automated reconstruction algorithms.
对于自动重建算法,这数据集的特色是在DIADEM挑战中(Brown et al., 2011)作为标准.
Figures 1A,B show representative image stacks from the OP and L6 datasets.
图1A,B显示了代表图像栈来自OP和L6数据集.
The initial traces are superimposed on the maximum intensity projections of the image stacks, and are slightly shifted for better visibility.
初始追踪是成阶层状的,预测在图像栈中的最大亮度,为了更好表现,稍微改变.
As can be seen, these initial traces accurately represent the geometry of neurites contained in the image stacks.
这些初始追踪精确表达了在图像栈中的神经的几何形状.
However, a closer examination of the L6 trace topology reveals numerous erroneously merged (stolen) branches.
然而,更接近L6追踪拓扑的检查揭露了更多错误的合并的神经分支.
Such errors in the initial trace often occur when the neurites belonging to different trees appear to be in contact due to poor z-resolution or due to high density of labeled structures.
例如错误在初始追踪时常发生,当属于不同树的神经,彼此联系,由于匮乏的z解决方案或是由于标记结构的高密度.
Presence of these topological errors becomes evident after labeling distinct tree structures with different colors (Figure 1C).
在用不同颜色标记树清晰的结构后,这些拓扑学错误的出现变成明显.
The second part of our automated tracing algorithm uses a machine learning approach that actively learns the morphology of neurites in an attempt to resolve the errors present in the initial trace (see Figure 1D).
我们自动追踪算法的第二部分用了机器学习方法,主动学习神经的形态,尝试去解决初始化追踪出现的错误(见图1D).
Comparison of Automated Initial Traces and Manual User Traces
比较自动化初始追踪和手工用户追踪
Below we evaluate how well automated and manual traces capture the layout (geometry) of the neurites in the image stack, as well as how well they represent the morphology of branching tree structures (topology).
在图像栈中,评估自动化和手工追踪获取神经形态布局哪个更好,也就是他们谁更能代表分支树结构的形态(拓扑).
Similar comparisons have been carried out in other studies (Gillette et al., 2011a; Choromanska et al., 2012;Mayerich et al., 2012).
相似的比较已经得到在其他研究成果中.(Gillette et al., 2011a; Choromanska et al., 2012;Mayerich et al., 2012).
Each OP and L6 image stack was traced automatically using the Fast Marching algorithm as well as manually by three trained users.
每一个OP和L6图像栈是自动追踪用快速行进算法也让三个熟练用户手工追踪.
Figure 6A shows an example of the resulting four traces of a single OP stack. Inevitably, imperfect labeling and limited resolution of optical microscopy lead to uncertainties in tracing.
图6A显示出单个OP栈的4个追踪的例子结果.不可避免的,不完美的标记以及光学显微镜的缺陷导致不可信的追踪.
Trained users often resolve such uncertainties differently from one another, and hence no single trace can be viewed as a gold standard.
熟练用户常常分解例如不能确定的不同,因此没有单追踪作为黄金标准.
Thus, we had to first establish quantitative measures describing the baseline inter-user variability, and only then evaluate the performance of the automated tracing algorithm in comparison to this baseline.
因此,我们不得不首次建立定量测量去描述基线用户间变异性,和评估自动追踪算法的性能的比较标准.
To this end, each manual trace was chosen to be the gold standard and compared to the automated trace and the remaining two manual traces. This led to 6 inter-user and 3 automated-to-user trace comparisons for each stack.
最后,每一个手工追踪最终都被选择为黄金准则,去比较自动追踪算法,和剩余两个手工追踪.对于每个栈来说,有了6个用户间和3个机器与人工的追踪比较.
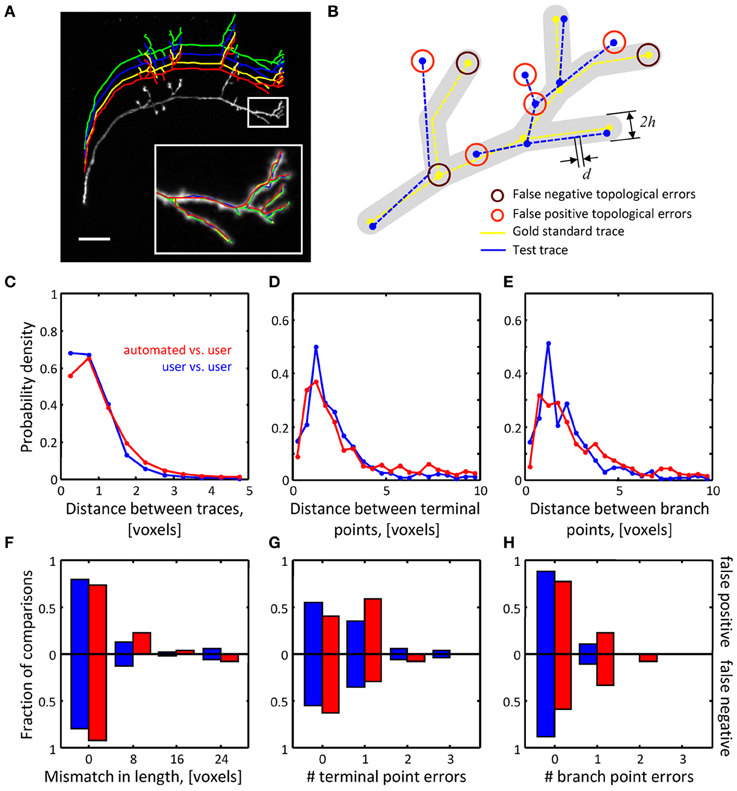
Figure 6. Assessing the quality of automated traces. (A) Three manual traces (green, blue, and yellow) and one automated trace (red) are superimposed on a maximum intensity projection of an OP neuron.
图6,通过自动化的才能,(A)三个手工用户(绿,蓝,黄)和一个自动追踪(红)是成阶层在op神经元的最大亮度中.
The traces are staggered upward for better visibility. The inset shows a zoomed view of the boxed region. Scale bar is 20 μm.
该追踪是错开排列的为了更好显示.该插图显示了盒范围的升视角.比例尺是20μm.
(B) Several geometrical and topological features are used to compare traces. Gold standard trace (yellow) and test trace (blue) are shown.
(B)比较追踪是通过几个几何学和拓扑学的特点.黄金准则(黄)和测试追踪(蓝)如图.
Both traces are composed of nodes connected by edges of length d. Nodes on these traces are referred to as corresponding nodes if they are located within distance h of each other (d << h).
追踪都是由长度d边缘连接的节点组成的.如果节点位于相距h范围内,追踪的节点被称为对应的节点.
Circles highlight false negative and false positive branch and terminal points. (C–E) Automated traces reliably capture the geometry of neurites.
高亮圆表示错误的分支与末端节点.(C-E)自动追踪确实获取了神经的形态.
Nine OP axons were reconstructed with NCTracer, first automatically and then manually by three trained users.
9个OP轴突由NCTracer重建,首先自动然后由三个受训用户手工重建.
The probability densities for distances between the corresponding trace nodes (C), terminal points (D), and branch points (E) were used as metrics for geometrical comparisons.
这个可能性密度距离在相对应追踪节点(C),末端节点(D),和分支节点(E)作为材料进行形态比较.
Red lines show the results of automated-to-user trace comparisons. Here, all user traces for every stack were used one by one as the gold standard, leading to 27 automated-to-gold standard trace comparisons.
红线表示机器与人工追踪的比较结果.所有用户追踪对于每一个栈都一比一作为黄金准则,有27机器与黄金准则追踪的比较。
The results were pooled. Blue lines show similar results based on 54 user-to-user trace comparisons.
这结果是贫乏的。蓝线表示基于54个用户与用户的追踪比较的相似的结果
(F–H) Automated traces accurately represent the topology of OP neurons. Three topological measures were compared: false positive/negative trace lengths (F), numbers of false positive/negative terminal (G) and branch (H) points.
(F-H)自动追踪精确代表了OP神经数据集的拓扑结构。比较三个拓扑结果的测量得出:错误分支与末端节点(F)的长度,错误分支与末端节点(G)与分支节点(H)的数量。
Red and blue bars show the fractions of automated-to-user (n = 27) and user-to-user (n = 54) comparisons for different error types.
红与蓝条显示了机器与用户(n=27)与用户对用户(n=54)的部分比较有不同的错误类型。
The fractions for false positive and false negative errors are indicated with the bars above and below the x-axes.
错误的分支与末端节点的分数用高于x轴的条与低于x轴的条来表示。
To ensure the uniformity of the reconstructed dataset, all traces were subdivided into segments of equal length (d = 0.25 voxels).
为了确保重建数据集的一致性,所有追踪再分成等长的片段(d=0.25voxels).
To compare a pair of traces (a test trace and a gold standard trace) we perform a bi-directional nearest neighbor search to find corresponding nodes,
为了比较两者的追踪(测试的追踪和黄金准则的追踪)我执行双流向最近邻接搜索去发现相应的节点,
i.e., nodes on the two traces separated by less than h = 10 voxels (see Figure 6B).
在两个追踪,节点被分开于少于十个体积像素(见图6B).
A node in the test trace which has (does not have) a corresponding node in the gold standard trace is referred to as a true (false) positive node.
在测试追踪中,在黄金准则追踪线路,有一个相对应的节点的一个节点是作为一个真的积极节点.
A node in the gold standard trace for which there is no corresponding node in the test trace is referred to as a false negative node.
在黄金准则追踪中的,没有相对应的一个节点在测试追踪中作为一个假的消极节点.
Short terminal branches (less than 12 voxels) and dim branches (average intensity less than 0.12) were excluded from the comparisons.
短末端分支(少于12体积像素)和暗淡分支(平均亮度少于0.12)是被排除于比较的.
Results of the geometrical comparisons between automated initial traces and manual traces for the OP image stacks are shown in Figures 6C–E.
在OP图像栈,自动化初始追踪与手工追踪的几何学比较结果显示在图6C-E上.
The plots show probability densities of distances between corresponding nodes, corresponding branch points, and corresponding terminal points for both inter-user (blue lines),
计划显示了距离上可能的密度在相对应的节点,相对应的分支点和相对应的末端节点对于两者的内部用户(蓝线).
as well as automated-to-user comparisons (red lines). The geometrical precision of the automated and manual traces is evidenced by the fact that 95% of distance values lie below 2.3 voxels in Figure 6C, 7.3 voxels in Figure 6D,
和机器与用户的对比(红线).这个自动化追踪和手工追踪的几何精密是由事实来评估的:95%的距离值都小于2.3体积像素在图6C,7.3体积像素在图6D,
and 6.6 voxels in Figure 6E. More importantly, the difference between mean distances for the inter-user and automated-to-user comparisons (0.19, 0.51, and 0.65 voxels respectively) is smaller than the resolution of the image,
和6.6体积像素在图6E.更重要的是,用户间和机器与用户之间的比较的真实距离的不同时远小于图像的分辨率的.
and thus should have little bearing on trace dependent measurements. Similar conclusions were drawn from the geometrical comparisons of automated and manual traces of the L6 dataset (Figures 7A–C).
因此,应该有小误差在追踪中使用的尺寸.相似的结论由L6数据集中机器与手工追踪形态学比较中可以得出(图7A-C).
FIGURE 7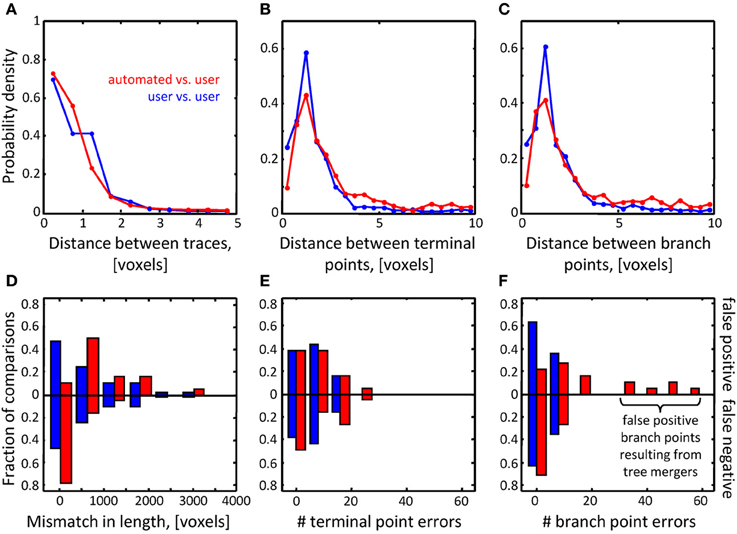
Figure 7. Assessment of initial traces of multiple neuron axons. Six L6 image stacks were reconstructed manually and automatically with NCTracer (see Figure 6 legend for details).
图7,多神经轴突的初始化追踪的评估.6个L6图片栈是由NCTracer手工和自动化重建的.
(A–C) Automated traces reliably capture the geometry of neurites. The probability densities for distances between the corresponding trace nodes (A),
(A-C)自动化追踪可靠地捕获神经的形态.在相对应追踪节点(A)之间的距离有可能性密度,
terminal points (B), and branch points (C) were used as metrics for geometrical comparisons. Red lines (n = 18) and blue lines (n = 36) show the results of automated-to-user and user-to-user trace comparisons.
末端点(B)和分支点(C)是作为几何比较的指标.红线(n=18)和蓝线(n=36)显示了自动化与用户和用户与用户追踪比较的结果.
(D–F) While the automated traces capture the geometry of the neurites well, they contain a markedly large number of false positive branch points (F).
(D-F)当自动追踪捕获神经形态学时,它们包含了一个极大数量的假正分支点(F).
These topological errors result from erroneous mergers of distinct axons that pass in close proximity of one another.
这些拓扑错误是由于在彼此接近的且明显轴突中错误合并.
Topological errors that occur due to incorrectly merged branches are more difficult to detect and can be detrimental to circuit reconstruction projects.
发生拓扑错误是由于检测错误的分支合并是比较困难的,还可能对线路重建项目不利.
Three measures were selected to quantify the extent of such errors: false positive/negative trace lengths, numbers of false positive/negative terminal points, and numbers of false positive/negative branch points.
使用了三项措施去量化这些错误的程度:假正向/负向的追踪长度,假正向/负向的末端节点的数量,以及假正向/负向的分支节点的数量
The results of comparisons for the OP dataset (Figures 6F–H) show that similar numbers of topological errors were made by the algorithm and the users, and these numbers were generally small (less than one false positive/negative branch or terminal point per stack).
(图6F-H)对于OP数据集的比较结果显示拓扑错误的相似数量由于算法和用户造成的,这些数字通常小(小于每个栈中的一个假正向/负向分支或末端节点).
For the L6 image stacks, the mismatches in length for the automated and manual traces were similar (Figure 7D), indicating that the automated algorithm performed as well as trained users in tracing the majority (in terms of length) of labeled structures.
(图7D)对于L6图像栈,对于机器和手工追踪的长度错配是相似的,表明了自动算法的表现与熟练追踪标记结构(长度方面)的用户一致.
However, in contrast to manual traces, automated traces contained more false positive/negative terminal points (Figure 7E) and markedly larger number of false positive branch points (Figure 7F).
然而,与手工追踪相比,自动化追踪包含了更多假正向/负向末端节点(图7E)和更多的假正向分支节点(图7F).
The former errors result from branches that are broken due to imperfect labeling, while the latter arise from a specific artifact of the Fast Marching algorithm, i.e., merging nearby, but distinct branches.
前者错误是因为分支断裂由于不完美的标记,而后者是从快速行进算法的特定人工品,即,合并附近的分支但不同的分支结果.
In particular, lower z-resolution of an image stack makes such mergers more prevalent, leading to larger numbers of false positive branch points.
尤其,z轴的低分辨率的图像栈使得这种合并更加普遍,导致了更大数量的假正向分支节点.
Active Learning of Branching Morphology of Neurites
轴突分支形态的主动学习
To resolve the above mentioned topological errors, branches of the initial trace were disconnected from one another and merged into tree-like structures in an active learning approach described in the Methods section.
为了解决上述拓扑错误,初始追踪的分支是彼此断开的,在本文描述的主动学习方法中合并进类似树的结构.
Briefly, the positions of branch and terminal points were clustered based on distance, and branch merging was performed within every cluster independently (see Figure 4).
简单点,分支节点和末端节点的位置是基于距离进行聚群的,和独立地完成分支合并在每个集群中(见图4).
Perceptron and SVM classifiers were designed and trained online to accomplish the branch merging task generating the final traces of the OP and L6 image stacks.
感知器和SVM分类器被设计和在线训练去完成分支合并任务生成OP和L6图像栈的最终追踪.
To assess the performance of the classifiers, their generalization error rates were monitored as functions of the number of training examples.
为了评估分类器的性能,他们普遍错误比例作为训练实例数量的函数进行监测的.
Figures 8A,B compare the performance of the classifiers trained on randomly selected branch merging examples with that of classifiers trained in an active learning approach.
图8A,B 比较分类器的性能 训练在随机选择的分支合并例子的分类器 与 用主动学习方法训练的分类器
The plots show that the active learning approach provides a clear advantage in terms of the number of training examples required to reach a given error rate.
该图表明主动学习方法提供了清晰的优势,在达到给定的错误比率的训练例子的数量上.
For each dataset, error rates of less than 5% were achieved by both classifiers with less than 40 actively chosen training examples.
对于每一个数据集,小于40训练例子的分类器可以达到少于5%的错误率.
The rapid decline of the generalization error rate validates our choice of features used for the branch merging task (see Figure 3).
普通错误比率的迅速下滑证明了我们的选择–用于分支合并任务的特性(见图3).
As expected, trained SVM and perceptron classifiers established nearly identical decision boundaries, as judged by the distance between their normalized weight-vectors (0.29 for OP and 0.10 for L6).
如预期,受训的SVM分类器和感受器建立了几乎相同的决策边界,通过归一化权重矢量之间的距离来判断.
In contrast, between-dataset distances were larger (0.63 for perceptron and 0.63 for SVM), indicative of the fact that classifiers were able to capture dataset specific morphological information.
与此相反,数据集之间的距离[差距]是增大的(0.63的感受器和0.63的SVM),表明了分类器是可以捕获数据集特定形态信息的事实.
FIGURE 8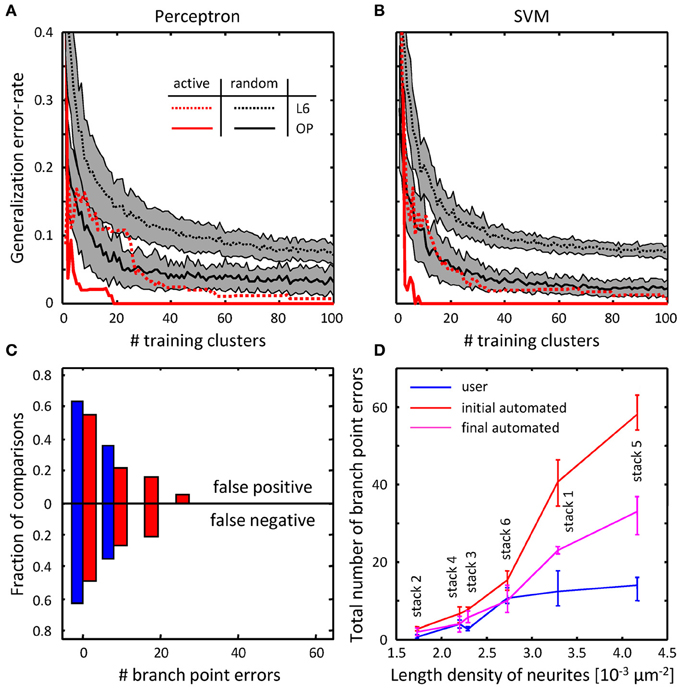
Figure 8. Online training can be used to reduce the numbers of topological errors present in initial traces.
图8 在线训练可以用于减少拓扑错误率在初始化追踪时的数量
(A) Generalization error-rate as function of the number of training clusters for the perceptron classifier.
(A) 普通错误比率作为训练感受分类器集群的功能指标.
Black lines (mean) surrounded by gray margins (standard errors) show the results of random training.
黑线(实线)由灰色边框(标准错误)显示随机训练的结果.
For each number of training clusters, training sets were generated at random 1000 times. Training was performed on each set of clusters, while testing was done on the remaining clusters.
为每一个集群的训练,训练集随机生成1000次,在每个组的集群进行培训,而剩余的集群用于测试.
Results for all 1000 experiments were averaged. Solid and dotted lines show the results for the OP and L6 datasets respectively.
平均1000次的实验结果.实线和虚线分别显示了OP和L6的数据集.
Red lines show the corresponding results for active training experiments. (B) Same for the SVM classifier.
红线显示了主动训练实验的结果.(B)与SVM分类器一样.
(C) The number of false positive branch points present in the initial trace of L6 dataset (Figure 7F) is greatly reduced by the branch merging algorithm.
(C)目前在L6数据集(图7F)初始化追踪时,通过分支合并算法大量减少了假正向分支节点.
(D) The sum of false positive and false negative branch point errors is an increasing function of length density of labeled neurites.
(D)假正向或假负向分支节点错误的总数是对标记的神经元轴突的长度密度的增函数.
Length density is calculated as the average length of neurites traced by the users divided by the image stack volume. Error-bars indicate the range of branch point errors.
长度密度的计算方法是 用户追踪的神经的平均长度 除以图像栈体积.
Automated tracing algorithm performs as well as trained users when the density of labeled neurites is low (<0.003 μm−2).
自动追踪算法的性能与与用户追踪在标记神经的亮度低时(<0.003μm−2).
Geometry and topology of the final automated traces produced by the branch merging algorithm were compared to the user traces in the manner described in Figures 6, 7.
最终自动追踪的几何和拓扑由用户追踪的方式(如图6,7所说)用分支合并算法生成.
No significant geometrical changes resulted from automated branch merging. This was expected, as trace modifications that accompany branch merging are confined to very local regions in the vicinity of branch or terminal points.
没有显著的形态改变是由于自动分支合并.如所期望的,作为追踪伴随着分支合并是被非常局限的区域所限制而修改,在分支或末端附近.
In addition, automated branch merging did not alter the topology of initial traces of OP neurites.
更多的,自动分支合并不会更改OP神经初始化追踪的拓扑.
The reason is that the initial traces of these morphologically simple structures did not contain significant topological errors in the first place (Figures 6F–H).
原因是在第一个地方,这些形态简单结构的初始追踪不会包含显著的拓扑错误(图6F-H).
As for the topology of L6 traces, no significant changes were observed in false positive/negative lengths (Figure 7D) and terminal point numbers (Figure 7E).
至于L6追踪的拓扑,在假正向/负向长度(图7D)和末端点数字(图7E),没有观察到显著的改变.
As was intended, automated branch merging greatly reduced the number of false positive branch points present in the initial traces (Figure 8C vs. Figure 7F).
正如预期的,自动分支合并大量减少了在初始化追踪时的假正向分支的数量(图8C与图7F).
Though the reduction in the number of false positive branch points was large (about two-fold), the branch merging algorithm failed to achieve the level of user performance (Figure 8C).
通过假正向分支点数量的减少(大概两倍),分支合并算法没有达到用户性能的级别(图8C)
To examine the reason behind this disparity we plotted the sum of false positive and false negative branch point errors for every L6 stack as function of length density of neurites contained in the stack (Figure 8D).
检查这种差距背后的原因是,我们绘制的假正向和假负向的分支点误差作为每L6栈作为包含在该栈的神经的密度长度的指标(图8D).
The length density is defined as the total length of traced neurites (in μm) divided by the stack volume (in μm3) and was calculated for each image stack by averaging over all user traces.
该长度比重被定义作为追踪神经的总长除以该栈体积(μm3单位)和被计算每个图像栈平均覆盖所有用户的追踪.
These comparisons show that in every stack the branch merging algorithm substantially reduced the total number of errors present in the initial trace.
这些比较显示了每一个栈,分支合并算法本质上都是减少初始化追踪的错误数量.
What is more, when the density of labeled neurites was small (less than 0.003 μm−2, e.g., Figure 1D), the resulting final automated traces were on par with user reconstructions.
此外,当标记神经的密度是小的(少于than 0.003 μm−2 图1D),最终自动化追踪的结果等同于用户重建.
Comparisons with Other Automated Tracing Tools
与其他自动追踪工具比较
The geometrical and topological measures used to evaluate the quality of automated traces were also used to compare the performance of NCTracer, Vaa3D (Xiao and Peng, 2013), and NeuronStudio (Rodriguez et al., 2009).
几何和拓扑测量用于评估自动追踪的质量,比较NCTracer,Vaa3D,NeuronStudio
To this end, automated traces of OP and L6 image stacks were obtained with Vaa3D and NeuronStudio. We visually inspected these traces and varied the software parameters to achieve good coverage and performance.
为此,OP和L6图像栈的自动追踪是由Vaa3D和NeuronStudio所获得的.我们视觉上检查这些追踪和验证软件参数是否达到最佳覆盖和性能.
Inter-user and automated-to-user comparisons were performed as previously described. To evaluate the geometry of automated traces we calculated the mean distances between corresponding nodes and corresponding terminal and branch points.
用户间和机器与用户间比较是如前所述.评估自动化追踪的几何,我们计算相对应的节点和相对应的末端节点和分支节点之间的真实距离.
To assess the topology of automated traces, we obtained the Miss-Extra-Score (MES) for trace length and for the numbers of terminal and branch points (Xie et al., 2011).
评估自动追踪的拓扑,我们获取了MES为了跟踪长度,和末端节点和分支节点的数量
Trace MES is defined as the ratio of the gold standard length reduced by the false negative length to the gold standard length increased by the false positive length.
追踪MES是定义作为黄金准则长度的范围,减少假负向长度,到黄金准则长度,增加假正向长度
Terminal and branch point MES are defined in a similar manner. The results of these comparisons are shown in Table 1.
末端节点和分支节点MES是定义在相似的方式.这些比较结果展示在表1.
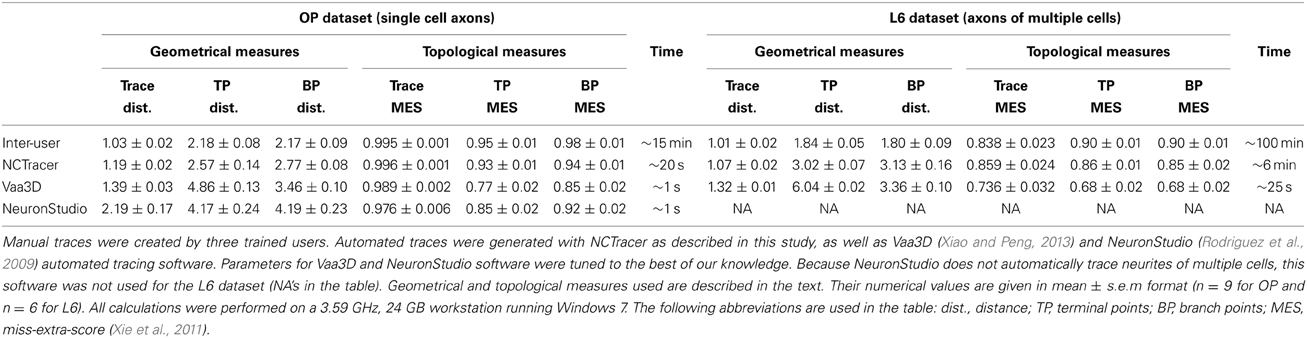
Smaller distance and higher MES indicate greater affinity between test and gold standard traces.
当距离越小,MES越高,说明它与黄金准则追踪越接近.
Table 1 shows that all automated tracing tools were able to capture trace geometry and topology of single OP axons reasonably well.
表1说明了所有自动追踪都可以正常获取到单OP轴突的形态和拓扑结构.
The advantage of the branch merging strategy proposed in this study becomes evident from examining the values of topological measures for L6 stacks, which contain multiple axons.
在包含多神经的L6栈的拓扑测量审核过程,分之合并策略优势变得明显.
According to these measures, NCTracer significantly outperforms other software. And in general, all geometrical and topological measures of NCTracer are closest to the inter-user measures.
根据这些测量,NCTracer很明显比其他软件好.总的来说,NCTracer在所有形态和拓扑测量中最接近用户间的测量.
Table 1 also shows a trade-off between the quality of automated traces and tracing time.
表1也显示了在自动追踪的质量与追踪时间的权衡.
Vaa3D and NeuronStudio are 15–20 fold faster than NCTracer.
Vaa3D 和 NeuronStudio 是都快于NCTracer 15到20个折叠.
We do not view this as a major drawback because tracing of single stacks with the current version of NCTracer can be easily performed on modern day workstations,
不将速度作为主要确定因为用最新版本的NCTracer单栈追踪可以很容易在现代工作站中运行.
while high-throughput projects could still be carried out on computer clusters.
而高通量工程还可以在计算机集群中运行.
Discussion
讨论
Much of our understanding of brain structure and function is derived from quantitative analyses of neuron shapes.
许多我们对大脑结构和功能的理解是起源于我们队神经形态上的定量分析.
Researchers routinely utilize partial or complete single cell reconstructions, as well as reconstructions of multiple cells often spanning several stacks of images in order to address various questions.
为了解决各种各样的问题,研究者常规利用部分或完全的单细胞重建,也多细胞重建常常生成图形栈.
Single cell reconstructions are often used in cell classification and comparative neuroanatomy studies, theoretical studies of neuron shapes, and detailed computational models of intracellular activity.
单细胞重建常常用于细胞分类和神经解剖学比较,神经形态的理论研究和细胞活性的精密计算模型.
Single cell reconstructions are frequently pooled in silico to simulate structural connectivity of local neural circuits.
单细胞重建常常汇集在硅肺去模拟局部结构上的神经环的连通性.
Reconstructions of multiple labeled cells are used for the analyses of synaptic connectivity in local circuits, in vivo studies of circuit plasticity, and large-scale brain mapping projects.
多标记细胞重建是用于在局部系统的突触的连通性的分析中,在体内系统可塑性研究,和大规模脑映射项目.
There is no doubt that automating the tracing process will advance these studies, significantly increasing their throughput and eliminating the biases and variability associated with manual tracing.
毫无疑问,自动追踪处理这些研究的优势,显著增加了它们的生产力,消除了手动追踪的偏差的变异性.
It is important to understand that it is usually not sufficient to obtain the basic layout of all labeled neurites.
通常是不能充分获取到所有被标记神经的基础布局的,明白它是重要的.
In particular, projects aimed at the analyses of synaptic connectivity require accurate knowledge of branching morphology of individual cells (Figure 1).
尤其是项目旨在突触连接的分析,需要分裂细胞中分支形态学上扎实的知识.
In this study, we use machine learning to evaluate topologically different scenarios of constructing automated traces (Figure 4A) and then determine the correct branching pattern based on previously learned morphological features.
在本研究中,我们用机器学习去评估自动重建追踪的不同事态(如图4A),和确定正确的分支模式基于之前所学习的形态学的特点.
A machine learning approach to image processing typically requires a large labeled set of examples, and creating such a set can be very time-consuming.
偏向图像处理的一个机器学习典型需要一个巨大标记集合例子,和创造非常耗时.
Our active learning strategy circumvents this problem by taking advantage of the combinatorial nature of the numbers of branch merging scenarios (Figure 4B).
我们主动学习的策略避免了采取大量分支合并情况的自然组合的问题.
Another advantage of this strategy is subtractive normalization, Equation (6). Branch merging scenarios are only compared within clusters, normalizing for the variations in local intensity and density of labeled neurites.
这个策略其他的优势是减法归一化-等式6.分之合并的方案不仅在集群中比较,还归一化标记的神经的局部强度和密度的变化.
The results of this study show that the quality of automated traces is strongly dependent on the length density of labeled neurites.
这项研究的结果表明,自动化追踪的质量高度依赖于标记的神经突的长度密度。
When this density is lower than 0.003 μm−2 the automated tracing algorithm performs on par with trained users (Figure 8D);
当该密度低于0.003μm-2时,自动跟踪算法与经训练的用户的表现相同(图8D);
the reliability of automated traces diminishes rapidly with increase in density beyond this point. Hence, proofreading and error-correction may be required for some automated traces.
自动追踪的可靠性随着密度的增加而迅速减小,超过该点上。 因此,对于一些自动化追踪可能需要校对和纠错。
Proofreading must be done in a computer guided manner, which is particularly important for high-throughput reconstruction projects.
校对必须以计算机引导的方式来完成,这对于高通量重建项目尤为重要。
The confidence measure described in Equation (10) can be used to convey information about the certainty in the outcome of automated tracing.
等式(10)中描述的置信度度量可以用于传达关于自动跟踪的结果的准确度信息。
This measure can be calculated for every vertex in the trace and can be used to direct the user’s attention to the most uncertain parts of the trace.
该度量可以针对追踪中的每个顶点进行计算,并且可以将用户的注意力引导到追踪的最不确定的部分。
Only the lowest confidence mergers will need to be examined by the user, leading to a substantial reduction in proofreading time.
只有最低置信度合并将需要由用户检查,校对时间的显着减少。
Such low confidence regions can be highlighted automatically and the user would choose from an ordered set of best alternative scenarios (based on decreasing confidence).
低置信区域会被自动高亮,用户将从最佳替代方案的有序集合中选择(基于降低的置信度)。
With the automation of tracing and proofreading it should be possible to map intact, sparsely labeled circuits on the scale of a whole brain, e.g.
利用自动化跟踪和校对,应该能够完成映射,例如在整个的大脑的稀疏标记的电路。
in the fly or the mouse. Consider a hypothetical experiment of mapping structural connectivity in the mouse brain. The adult mouse brain is roughly 500 mm3 in volume (Ma et al., 2005).
在苍蝇或老鼠,考虑到在小鼠大脑中映射结构连通性的假设实验。 成年小鼠脑体积约为500mm 3(Ma et al。,2005)。
Subsets of mouse neurons can be labeled in vivo to reveal the layout of their axonal and dendritic arbors.
小鼠神经元的子集可以在体内标记,以显示其轴突和树突状突触的布局。
The brain can then be divided into 0.5 × 0.5 × 0.1 mm3 optical sections, and imaged in 3D with two-photon or confocal microscopy at 0.5 × 0.5 × 1.0 μm3 spatial resolution.
大脑可以分为0.5×0.5×0.1 mm3的光学切片,并在3D中用双光子或共聚焦显微镜以0.5×0.5×1.0μm3的空间分辨率成像。
This procedure would result in 20,000 stacks of images, each composed of 1000 × 1000 × 100 voxels, totaling 2 TB of raw imaging data.
该过程将产生20,000个图像堆叠,每个图像由1000×1000×100个体素组成,总共2TB的原始成像数据。
A dataset of this size would have to be reconstructed on a high-performance computer cluster, and the results could be viewed and proofread on modern-day workstations.
这种大小的数据集必须在高性能计算机集群上重建,可在现代工作站上查看和校对结果。
Depending on the density of labeling, reconstruction of a single stack may take on the order of 1 core-hour, or 20,000 core-hours for the entire brain.
根据标记的密度,单个堆叠的重建可能需要大约1个核心/小时,整个大脑需要20,000个核心/小时。
Thus, whole mouse brain mapping is no longer an unfeasible goal.
因此,整个小鼠的脑映射不再是一个不可能的目标。
Brain mapping at a much lower spatial resolution has long been performed with diffusion tensor imaging (DTI).
极低空间分辨率的大脑映射解决方案已经用扩散张量成像(DTI)完成。
This non-invasive technique measures the diffusion tensor associated with anisotropic movement of water molecules along white matter fiber bundles.
这种非侵入式扩散张量测量技术可以与沿着白质纤维束的各向异性运动的水分子相联系。
Numerous algorithms have been developed to construct tracts from such information, establishing coarse-grain connectivity between brain regions (for review see Le Bihan, 2003; Hasan et al., 2011; Soares et al., 2013).
许多算法已经发展出从相关信息中构造域,如建立脑区之间的粗粒连接 (for review see Le Bihan, 2003; Hasan et al., 2011; Soares et al., 2013).
Such algorithms typically use streamline tractography to connect voxels of similar tensor-field orientations into a trace.
这种算法通常使用流线纤维成束连接相似张量场方向的体积像素进轨迹中.
The reconstruction problem encountered in DTI is somewhat related to the problem of neurite tracing described in this study; however, there is an important difference.
在扩散张量成像这个重建问题与在本研究描述的神经突触追踪问题有关,然而这有重要的不同.
Due to the relatively low resolution of DTI (typically 1 mm3 per voxel) there is no anatomical basis for trying to detect branching patterns in DTI tracts.
由于相对低分辨率的DTI(典型是每体积像素1立方毫米),在DTI追踪中尝试去发现分支模式,这是没有解剖学基础的。
Hence, unlike neurite tracing, where topological errors may have a catastrophic effect on the overall connectivity map, the results of DTI tracing are expected to be less sensitive to such errors.
因此,不像神经突触的追踪,拓扑错误会灾难性的影响全部连接映射,DTI追踪结果显示对这类错误不敏感.
It remains to be seen to what extent brain mapping at single neuron resolution correlates with the connectivity maps established with DTI.
尚待分晓的是用DTI单神经分辨率测量相连接的大脑映射能建立到什么程度。
Conflict of Interest Statement
利益冲突声明
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
作者宣布,该研究是在没有任何商业或财务关系,这可能是一个潜在的利益冲突。
Acknowledgments
致谢
We thank Vivek Mehta and Paarth Chothani for their significant contributions to the design and development of the NCTracer software, and Soham Mody for testing and debugging the software.
谢谢Vivek Mehta 和 Paarth Chothani,他们重大贡献设计和开发的软件 NCTracer , 和 Soham Mody 为NCTracer软件测试和debugging.
Active training, automated tracing, and manual tracing of neurites in this study were performed with NCTracer.
在本研究中用NCTracer进行主动训练,自动跟踪和神经突触的手动跟踪。
Information on NCTracer can be found at www.neurogeometry.net.
NCTracer信息可以在www.neurogeometry.net发现.
This work was supported by the NIH grant NS063494.
该工作由NIH拨款NS063494支持.